ヘクサエディタでの解析
プログラムは突き詰めていけば0と1の羅列です。というわけで、今回は「ヘクサエディタでILの解析をしてみたいと思います。
対象のコード
.assembly extern mscorlib {}
.assembly hello {}
.method static public void main() cil managed
{
.entrypoint
.maxstack 2
ldstr "Hello world!"
ldstr "今日は世界"
call void [mscorlib]System.Console::
WriteLine(class System.String)
call void [mscorlib]System.Console::
WriteLine(class System.String)
ret
}
普通のコードです。下に一回アセンブルした後に逆アセンブルをかけたものも載せておきます。
// Microsoft (R) .NET Framework IL Disassembler. Version 1.1.4322.573
// Copyright (C) Microsoft Corporation 1998-2002. All rights reserved.
.assembly extern mscorlib
{
.ver 0:0:0:0
}
.assembly hello
{
.ver 0:0:0:0
}
.module test.EXE
// MVID: {D89197AA-6492-4D2B-AFFA-9F5CCA33FA8F}
.imagebase 0x00400000
.subsystem 0x00000003
.file alignment 512
.corflags 0x00000001
// Image base: 0x00d90000
// =============== GLOBAL FIELDS AND METHODS ===================
//Global methods
//~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.method public static void main() cil managed
{
.entrypoint
// コード サイズ 21 (0x15)
.maxstack 2
IL_0000: ldstr "Hello world!"
IL_0005: ldstr bytearray (CA 4E E5 65 6F 30 16 4E 4C 75 )
// .N.eo0.NLu
IL_000a: call void [mscorlib]System.Console::WriteLine(string)
IL_000f: call void [mscorlib]System.Console::WriteLine(string)
IL_0014: ret
} // end of global method main
// =============================================================
//*********** 逆アセンブリが完了しました ***********************
ここで一つ目のヒントがありますね。日本語文字列はバイト配列になる。らしいです。
ヘクサエディタでの閲覧
下に載せた図を見てください。とりあえず前半部分は普通のPE形式です。面白くありません。

文字列の場所を探る
文字列の場所を探ってみましょう。「今日は世界」の方の文字は逆コンパイル結果から分かっているのでこれで検索をかけてみます。
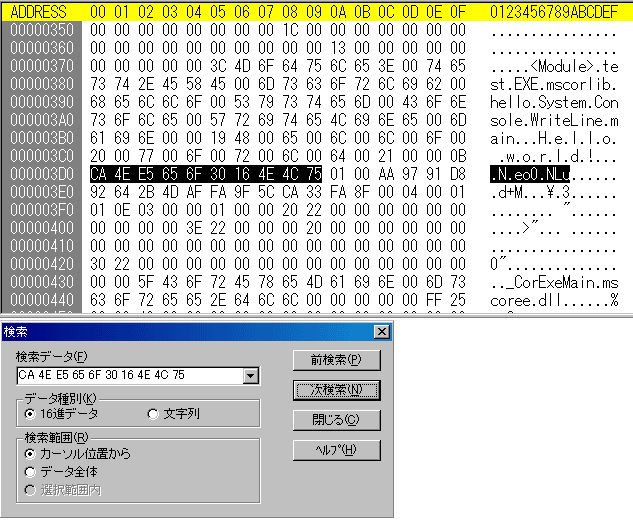
マッチしています。しかし、これが「今日は世界」になるとは思えませんね………。ああ、そうでしたUnicodeでしたね。

「Hello world!」の方は後ろに0が追加されています。
命令を解読する
今度は命令を読んでみましょう。「ldstr」は「0x72」です。「call」は「0x28」、「ret」は「0x2a」です。見つかりましたか?

完璧には分からなくても何となくなら分かると思います。
- 72 01 00 00 70 (ldstr)
- 72 1B 00 00 70 (ldstr)
- 28 01 00 00 0A (call)
- 28 01 00 00 0A (call)
- 2A(ret)
そのまま読めますね。「72,28」の後には4バイトの数値が書いてあります。恐らくアドレスでしょう。
ちょっと計算してみましょう。多分これはリトルエンディアンなので1,2のアドレスは次のようになります。
- 70 00 00 01
- 70 00 00 1B
- 00 00 00 1A
3番は2-1をしたものです。今度はヘクサエディタで文字の先頭アドレスを見ます。
- 00 00 03 B6
- 00 00 03 D0
- 00 00 00 1A
ぴったしです。まあ、こんな感じでしょう。恐らく実行時に正しいアドレスへとデータが配置されるのでしょう。
こんな感じでヘクサエディタでも読めることが明らかになりました。
ページの一番上へ
一覧に戻る
初版2006-4-9 最終2006-4-13
(c) 2006,Atelier Blue (Rito)
- 質問から意見、誤字訂正まで気軽に連絡してください。
- こちらに掲示板も用意しています。「プログラム掲示板」
- リンクに関してはご自由にどうぞ。
- 書いてある情報については、特に断り書きがない限り自由に使ってください。そのまま転載しても、書き換えたりして再利用してもかまいません。